|
|
|
|
|
|
|
|
|
|
|
|
|
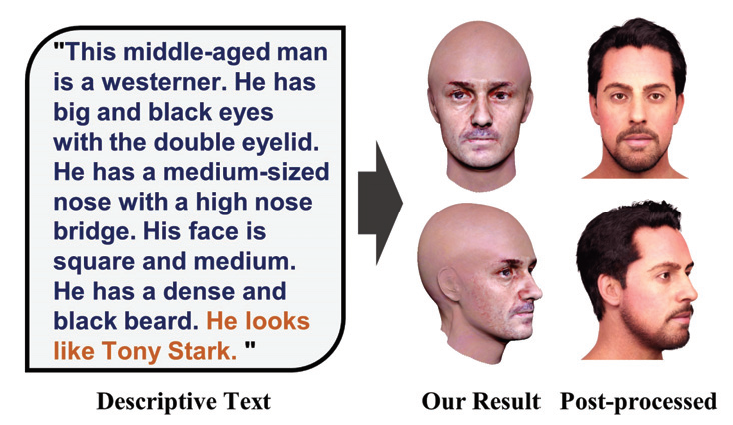
| Synthesizing high-quality 3D face models from natural language descriptions is very valuable for many applications, including avatar creation, virtual reality, and telepresence. However, little research ever tapped into this task. We argue the major obstacle lies in 1) the lack of highquality 3D face data with descriptive text annotation, and 2) the complex mapping relationship between descriptive language space and shape/appearance space. To solve these problems, we build DESCRIBE3D dataset, the first large-scale dataset with fine-grained text descriptions for text-to-3D face generation task. Then we propose a twostage framework to first generate a 3D face that matches the concrete descriptions, then optimize the parameters in the 3D shape and texture space with abstract description to refine the 3D face model. Extensive experimental results show that our method can produce a faithful 3D face that conforms to the input descriptions with higher accuracy and quality than previous methods. |
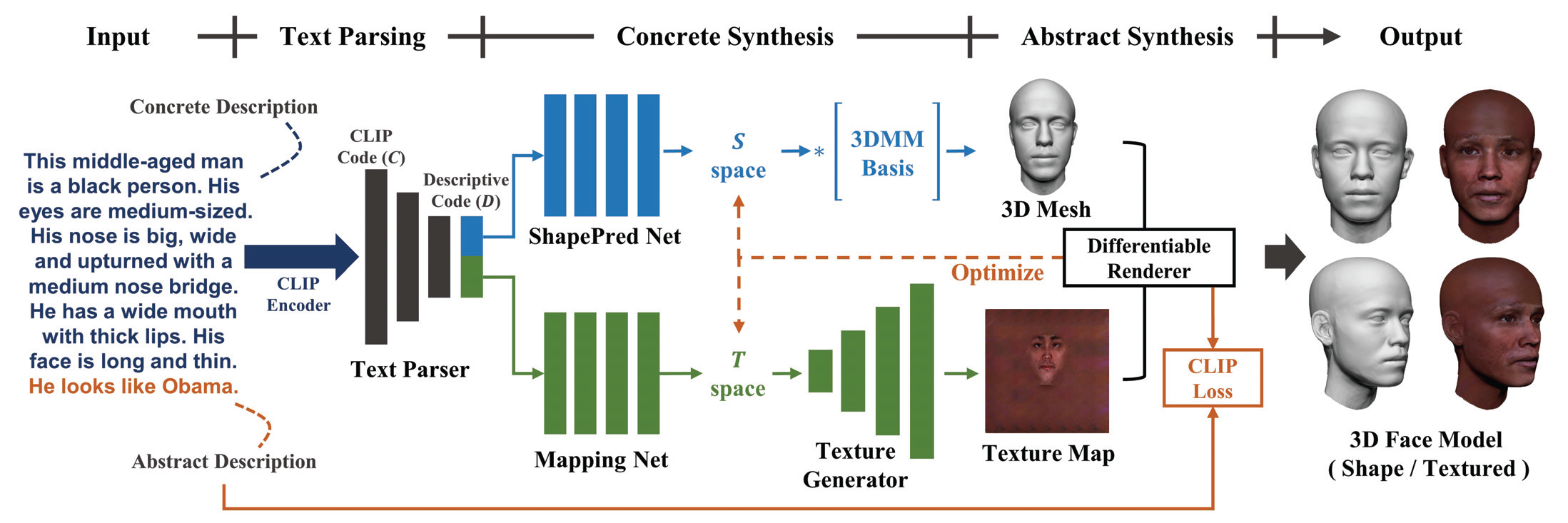 |
| Overview of our pipeline |
|
We introduce the DESCRIBE3D dataset, the first large-scale dataset with fine-grained text descriptions tailored for the text-to-3D face generation task. This dataset aims to address the scarcity of high-quality 3D face data with descriptive text annotations, which is a significant hurdle in the field. The DESCRIBE3D dataset provides a rich collection of 3D face models paired with detailed natural language descriptions, enabling more accurate and realistic 3D face generation from text inputs. License: To use the DESCRIBE3D dataset, you need to agree to our License. Please sign the License and send the signed PDF to nju3dv@nju.edu.cn. Download: After that, you can access the DESCRIBE3D dataset at Google Drive. |
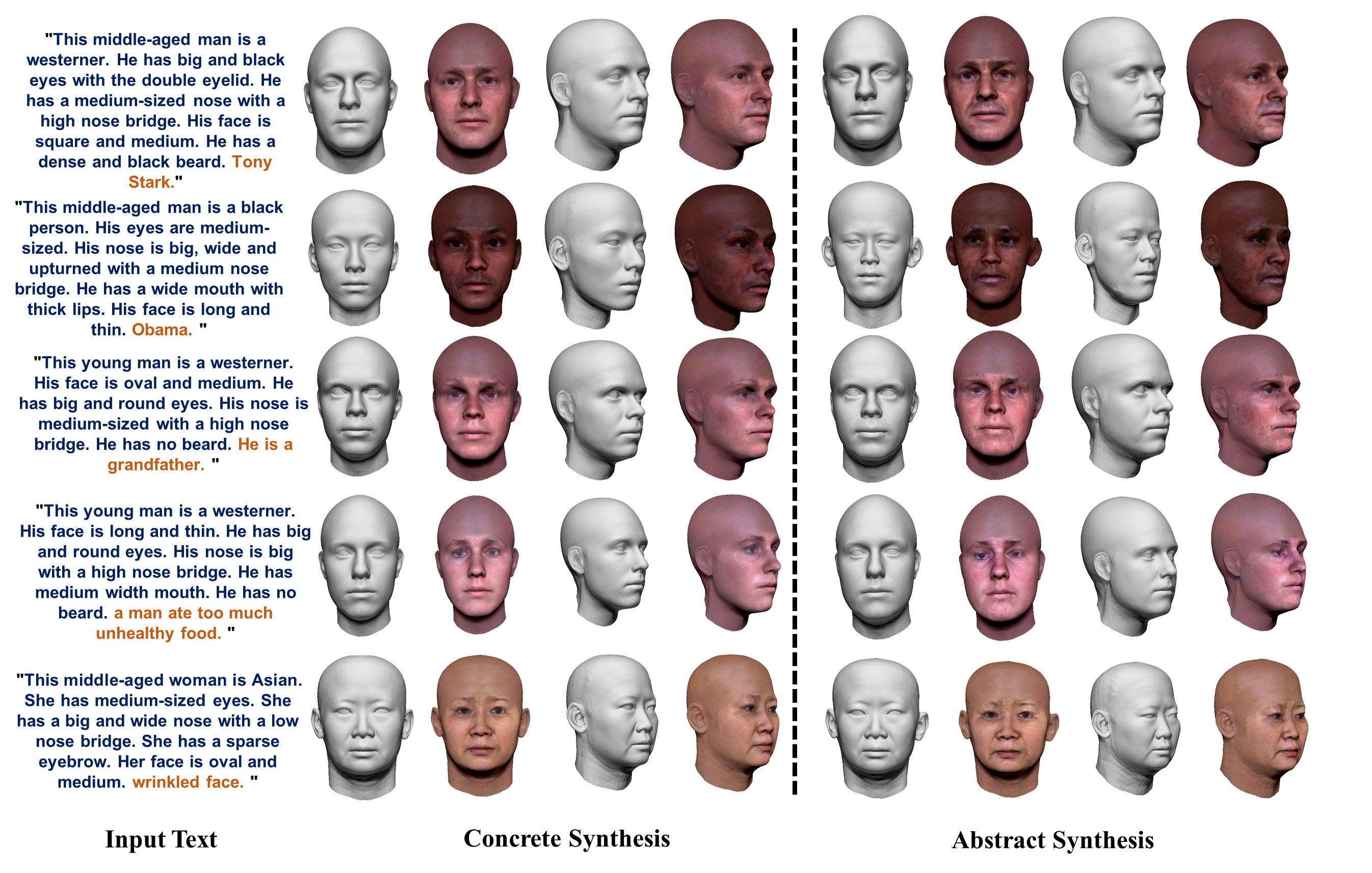 |
| Visual Result |
 |
High-fidelity 3D Face Generation from Natural Language Descriptions In Conference on Computer Vision and Pattern Recognition, 2023. (hosted on ArXiv) |
Acknowledgements |